
Detect High Data Drift¶
With this tutorial you: Understand how to use Eurybia to detect datadrift
This public dataset comes from :
https://www.kaggle.com/sobhanmoosavi/us-accidents/version/10
In this tutorial, the data are not loaded raw, a data preparation to facilitate the use of the tutorial has been done. You can find it here : https://github.com/MAIF/eurybia/blob/master/eurybia/data/dataprep_US_car_accidents.ipynb
[2]:
import pandas as pd
from category_encoders import OrdinalEncoder
import catboost
from eurybia import SmartDrift
from sklearn.model_selection import train_test_split
from sklearn import metrics
import numpy as np
/Users/78176D/workspace/eurybia/eurybia/report/generation.py:18: UserWarning:
Using Panel interactively in VSCode notebooks requires the jupyter_bokeh package to be installed. You can install it with:
pip install jupyter_bokeh
or:
conda install jupyter_bokeh
and try again.
Import Dataset and split in training and production dataset¶
[3]:
from eurybia.data.data_loader import data_loading
[4]:
df_car_accident = data_loading("us_car_accident")
[5]:
df_car_accident.head()
[5]:
| Start_Lat | Start_Lng | Distance(mi) | Temperature(F) | Humidity(%) | Visibility(mi) | day_of_week_acc | Nautical_Twilight | season_acc | target | target_multi | year_acc | Description | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 33.0 | -117.1 | 0.0 | 40.0 | 93.0 | 2.0 | 3 | Day | winter | 0 | 2 | 2019 | At Carmel Mountain Rd - Accident. |
| 1 | 29.5 | -98.5 | 0.0 | 83.0 | 65.0 | 10.0 | 4 | Day | summer | 1 | 3 | 2017 | At TX-345-SP/Woodlawn Ave/Exit 567B - Accident. |
| 2 | 32.7 | -96.8 | 0.0 | 88.0 | 57.0 | 10.0 | 0 | Night | summer | 0 | 2 | 2021 | Incident on RUGGED DR near BERKLEY AVE Expect ... |
| 3 | 40.0 | -76.3 | 0.0 | 61.0 | 58.0 | 10.0 | 4 | Day | spring | 0 | 2 | 2020 | At PA-741/Rohrerstown Rd - Accident. |
| 4 | 41.5 | -81.8 | 1.0 | 71.0 | 53.0 | 10.0 | 0 | Day | summer | 0 | 2 | 2020 | At 117th St/Exit 166 - Accident. |
[6]:
df_car_accident.shape
[6]:
(50000, 13)
[7]:
# Let us consider that the column "year_acc" corresponds to the reference date.
#In 2016, a model was trained using data. And in next years, we want to detect data drift on new data in production to predict
df_accident_baseline = df_car_accident.loc[df_car_accident['year_acc'] == 2016]
df_accident_2017 = df_car_accident.loc[df_car_accident['year_acc'] == 2017]
df_accident_2018 = df_car_accident.loc[df_car_accident['year_acc'] == 2018]
df_accident_2019 = df_car_accident.loc[df_car_accident['year_acc'] == 2019]
df_accident_2020 = df_car_accident.loc[df_car_accident['year_acc'] == 2020]
df_accident_2021 = df_car_accident.loc[df_car_accident['year_acc'] == 2021]
[8]:
#We will train a classification model to predict the severity of an accident. 0 for a less severe accident and 1 for a severe accident.
#Let's check percentage in class 0 and 1
pd.crosstab(df_car_accident.year_acc, df_car_accident.target, normalize = 'index')*100
[8]:
| target | 0 | 1 |
|---|---|---|
| year_acc | ||
| 2016 | 71.406287 | 28.593713 |
| 2017 | 67.254620 | 32.745380 |
| 2018 | 66.634662 | 33.365338 |
| 2019 | 79.551182 | 20.448818 |
| 2020 | 89.944804 | 10.055196 |
| 2021 | 98.259930 | 1.740070 |
[9]:
y_df_learning=df_accident_baseline['target'].to_frame()
X_df_learning=df_accident_baseline[df_accident_baseline.columns.difference(["target", "target_multi", "year_acc", "Description"])]
y_df_2017=df_accident_2017['target'].to_frame()
X_df_2017=df_accident_2017[df_accident_2017.columns.difference(["target", "target_multi", "year_acc", "Description"])]
y_df_2018=df_accident_2018['target'].to_frame()
X_df_2018=df_accident_2018[df_accident_2018.columns.difference(["target", "target_multi", "year_acc", "Description"])]
y_df_2019=df_accident_2019['target'].to_frame()
X_df_2019=df_accident_2019[df_accident_2019.columns.difference(["target", "target_multi", "year_acc", "Description"])]
y_df_2020=df_accident_2020['target'].to_frame()
X_df_2020=df_accident_2020[df_accident_2020.columns.difference(["target", "target_multi", "year_acc", "Description"])]
y_df_2021=df_accident_2021['target'].to_frame()
X_df_2021=df_accident_2021[df_accident_2021.columns.difference(["target", "target_multi", "year_acc", "Description"])]
Building Supervized Model¶
[10]:
features = ['Start_Lat', 'Start_Lng', 'Distance(mi)', 'Temperature(F)',
'Humidity(%)', 'Visibility(mi)', 'day_of_week_acc', 'Nautical_Twilight',
'season_acc']
[11]:
features_to_encode = [col for col in X_df_learning[features].columns if X_df_learning[col].dtype not in ('float64','int64')]
encoder = OrdinalEncoder(cols=features_to_encode)
encoder = encoder.fit(X_df_learning[features])
X_df_learning_encoded=encoder.transform(X_df_learning)
[12]:
Xtrain, Xtest, ytrain, ytest = train_test_split(X_df_learning_encoded, y_df_learning, train_size=0.75, random_state=1)
[13]:
train_pool_cat = catboost.Pool(data=Xtrain, label= ytrain, cat_features = features_to_encode)
test_pool_cat = catboost.Pool(data=Xtest, label= ytest, cat_features = features_to_encode)
[14]:
model = catboost.CatBoostClassifier(loss_function= "Logloss", eval_metric="Logloss",
learning_rate=0.143852,
iterations=300,
l2_leaf_reg=15,
max_depth = 4,
use_best_model=True,
custom_loss=['Accuracy', 'AUC', 'Logloss'])
model = model.fit(train_pool_cat, plot=True,eval_set=test_pool_cat, verbose=0)
[15]:
proba = model.predict_proba(Xtest)
print(metrics.roc_auc_score(ytest,proba[:,1]))
0.764435761049811
Use Eurybia for data validation¶
[16]:
from eurybia import SmartDrift
[17]:
SD = SmartDrift(df_current=X_df_2017,
df_baseline=X_df_learning,
deployed_model=model, # Optional: put in perspective result with importance on deployed model
encoding=encoder # Optional: if deployed_model and encoder to use this model
)
[18]:
%time
from datetime import date
SD.compile(full_validation=True, # Optional: to save time, leave the default False value. If True, analyze consistency on modalities between columns.
date_compile_auc = date(2007,1,1),#'01/01/2017', # Optional: useful when computing the drift for a time that is not now
datadrift_file = "car_accident_auc.csv" # Optional: name of the csv file that contains the performance history of data drift
)
CPU times: user 1 μs, sys: 0 ns, total: 1 μs
Wall time: 1.91 μs
INFO: Shap explainer type - <shap.explainers._tree.TreeExplainer object at 0x11ff09400>
The computed AUC on the X_test used to build datadrift_classifier is equal to: 0.6648471037089818
car_accident_auc.csv did not exist and was created.
As soon as compile() method, Eurybia displays default consistency checks as warnings. If some modalities are not present during training and are in production dataset, the deployed model will consider them wrongly. Inversely, if some modalities are present during training and are not in production dataset, it means that some profiles are missing.
[19]:
SD.generate_report(
output_file='report_car_accident_datadrift_2017.html',
title_story="Data drift",
title_description="""Car accident Data drift 2017""", # Optional: add a subtitle to describe report
project_info_file="../../eurybia/data/project_info_car_accident.yml" # Optional: add information on report
)
Eurybia is designed to generate an HTML report for analysis, and less for use in notebook mode. However, to illustrate functionalities, we will detail results with notebook mode analysis.
First Analysis of results of the data drift¶
Data driftn methodology is based on the ability of a model to discriminate whether an individual belongs to one of the two datasets. For this purpose a target 0 is assigned to the baseline dataset and a target 1 to the current dataset. Then a classification model (catboost) is learned to predict this target. The level of capacity of the data drift classifier to detect if an individual belongs to one of the 2 datasets represents the level of difference between the 2 datasets
Detection data drift performance¶
[ ]:
#Performance of datadrift classifier
SD.plot.generate_indicator(fig_value=SD.auc, height=300, width=500, title="Datadrift classifier AUC")
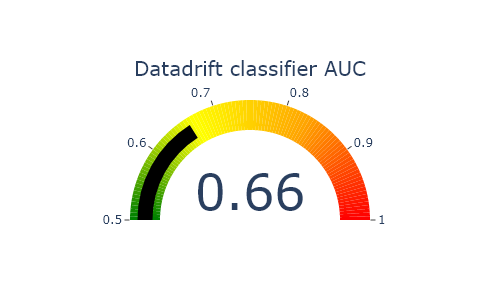
An Auc close to 0.5 means that there is little drift
Importance of features in data drift¶
This graph represents the variables in the data drift classification model that are most important to differentiate between the two datasets.
[ ]:
SD.xpl.plot.features_importance()
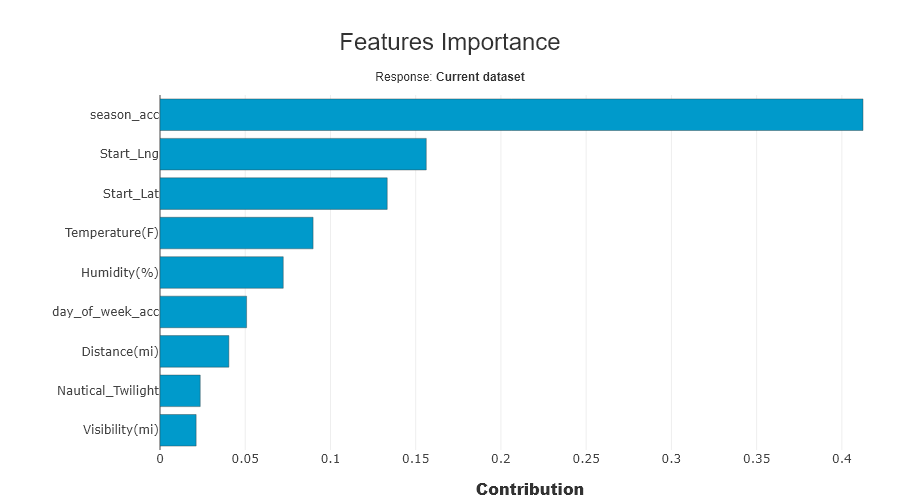
We get the features with most gaps, those that are most important to analyse. With date bias introduced, it is normal that date features are the most impacted. We will then decide to remove them. Let’s analyse other important variables
Feature importance overview¶
This graph compares the importance of variables between the data drift classifier model and the deployed model. This allows us to put into perspective the importance of data drift in relation to the impacts to be expected on the deployed model. If the variable is at the top left, it means that the variable is very important for data drift classification, but that the variable has little influence on the deployed model. If the variable is at the bottom right, it means that the variable has little importance for data drift classification, and that the variable has a lot of influence on the deployed model.
[ ]:
SD.plot.scatter_feature_importance() # works if deployed_model is filled
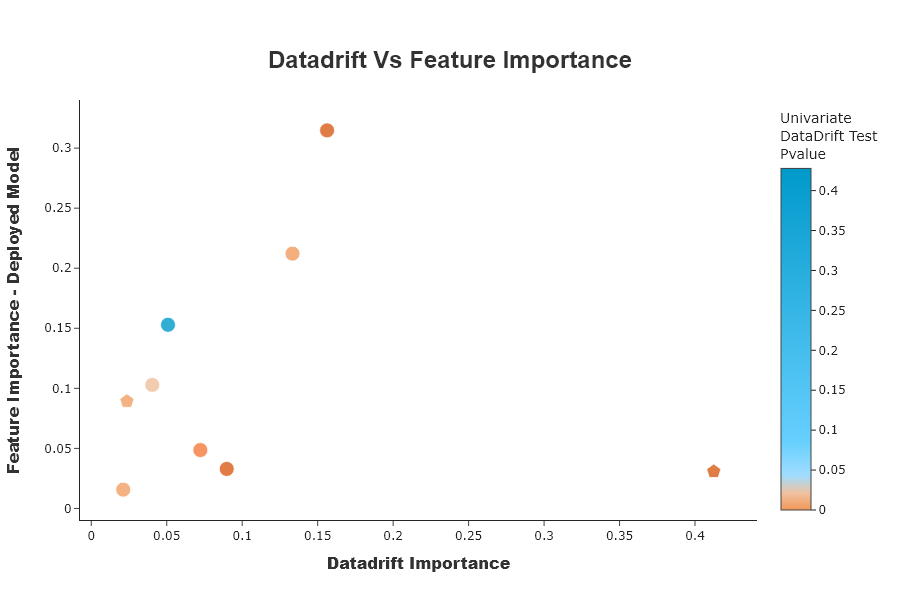
Putting importance of the drift into perspective according to the importance of the model to be deployed, can help the data scientist to validate that his model can be deployed.
Univariate analysis¶
This graphs shows a particular feature’s distribution over its possible values. In the drop-down menu, the variables are sorted by importance of the variables in the data drift classification. For categorical features, the possible values are sorted by descending difference between the two datasets.
[ ]:
SD.plot.generate_fig_univariate('season_acc')
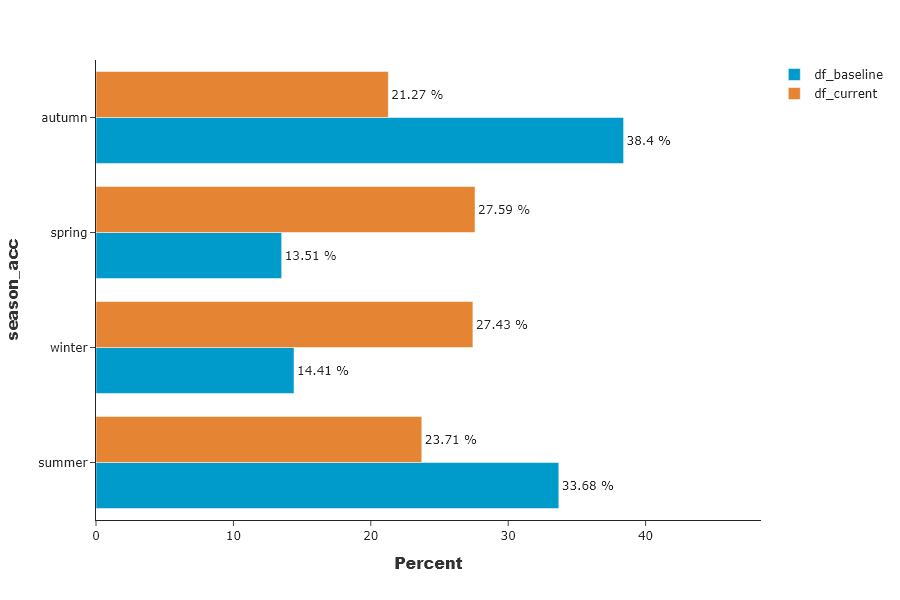
Distribution of predicted values¶
This graph shows distributions of the production model outputs on both baseline and current datasets.
[ ]:
SD.plot.generate_fig_univariate(df_all=SD.df_predict,col='Score',hue="dataset") # works if deployed_model is filled
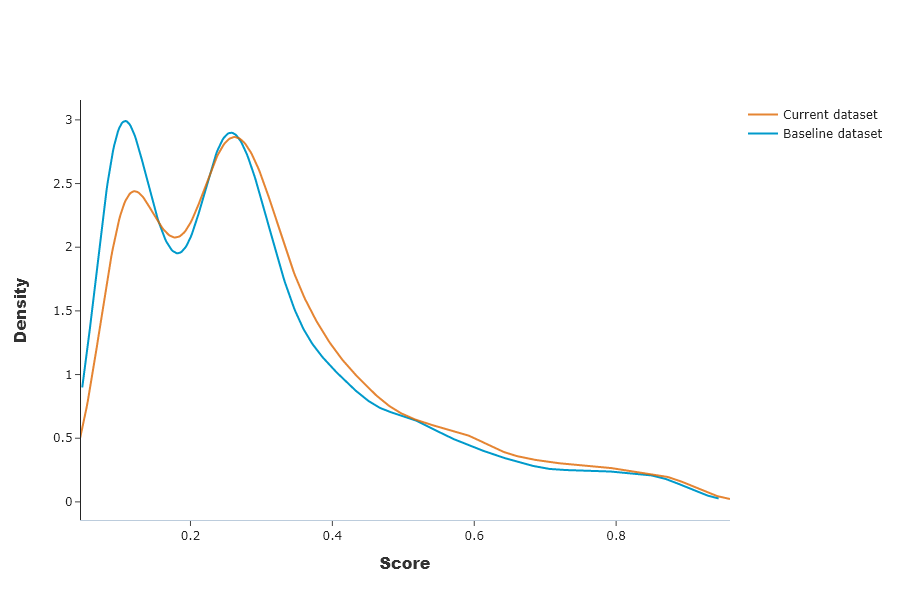
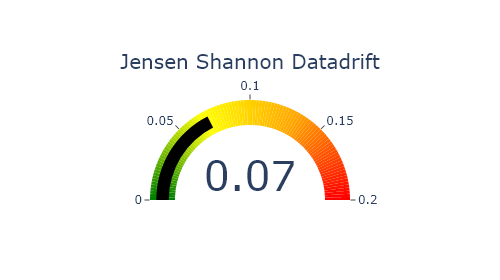
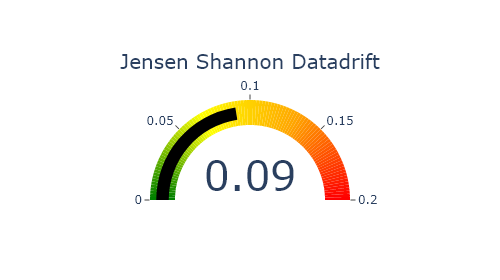
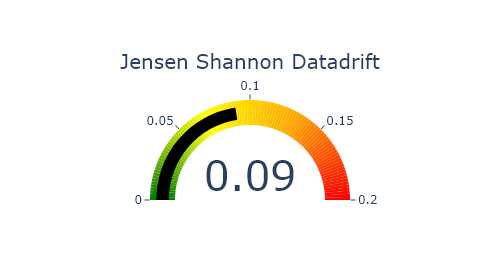
Jensen Shannon Divergence (JSD). The JSD measures the effect of a data drift on the deployed model performance. A value close to 0 indicates similar data distributions, while a value close to 1 tend to indicate distinct data distributions with a negative effect on the deployed model performance.
[ ]:
SD.plot.generate_indicator(
fig_value=SD.js_divergence,
height=280,
width=500,
title="Jensen Shannon Datadrift",
min_gauge=0,
max_gauge=0.2,
) #works if deployed_model is filled
Compile Drift over years¶
Compile Drift et generate report for Year 2018¶
[26]:
SD = SmartDrift(df_current=X_df_2018,
df_baseline=X_df_learning,
deployed_model=model, # Optional: put in perspective result with importance on deployed model
encoding=encoder # Optional: if deployed_model and encoder to use this model
)
[27]:
SD.compile(full_validation=True, # Optional: to save time, leave the default False value. If True, analyze consistency on modalities between columns.
date_compile_auc = date(2018,1,1), # Optional: useful when computing the drift for a time that is not now
datadrift_file = "car_accident_auc.csv" # Optional: name of the csv file that contains the performance history of data drift
)
INFO: Shap explainer type - <shap.explainers._tree.TreeExplainer object at 0x11965e990>
The computed AUC on the X_test used to build datadrift_classifier is equal to: 0.7047381011643021
[ ]:
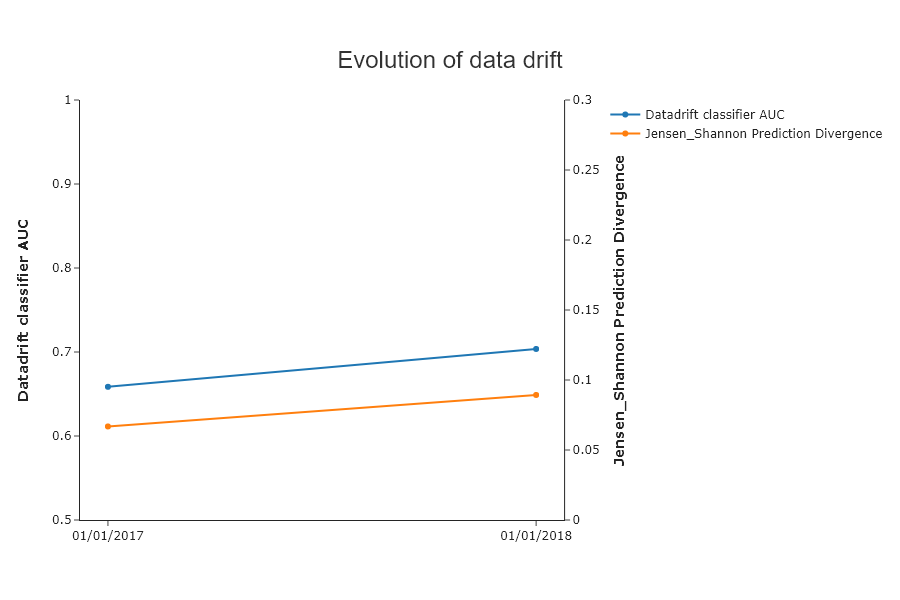
SD.plot.generate_historical_datadrift_metric() # works if date_compile_auc and/or datadrift_file are filled
[ ]:
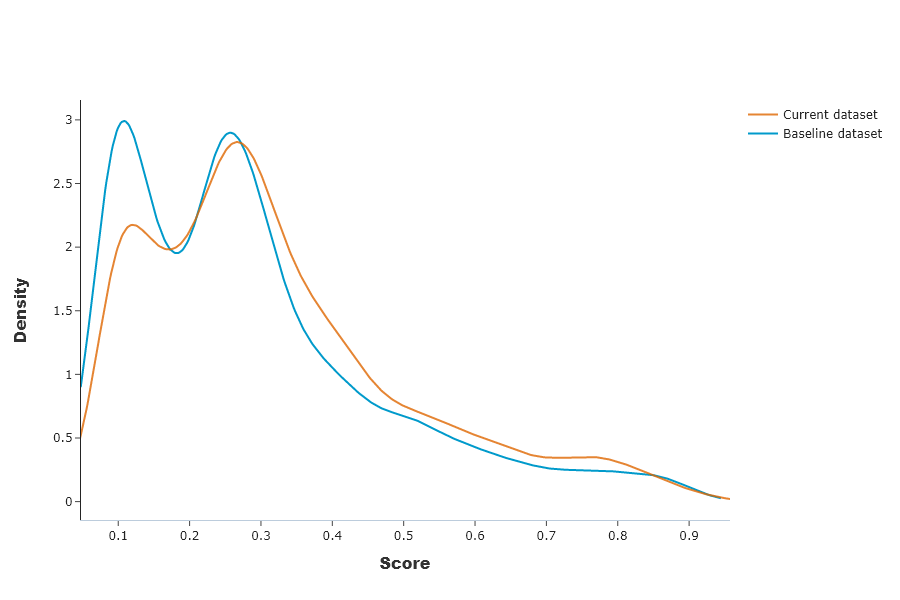
SD.plot.generate_fig_univariate(df_all=SD.df_predict,col='Score',hue="dataset") # works if deployed_model is filled
[ ]:
SD.plot.generate_indicator(
fig_value=SD.js_divergence,
height=280,
width=500,
title="Jensen Shannon Datadrift",
min_gauge=0,
max_gauge=0.2,
) # works if deployed_model is filled
Compile Drift et generate report for Year 2019¶
[31]:
SD = SmartDrift(df_current=X_df_2019,
df_baseline=X_df_learning,
deployed_model=model, # Optional: put in perspective result with importance on deployed model
encoding=encoder # Optional: if deployed_model and encoder to use this model
)
[32]:
SD.compile(full_validation=True, # Optional: to save time, leave the default False value. If True, analyze consistency on modalities between columns.
date_compile_auc = date(2019,1,1), # Optional: useful when computing the drift for a time that is not now
datadrift_file = "car_accident_auc.csv" # Optional: name of the csv file that contains the performance history of data drift
)
INFO: Shap explainer type - <shap.explainers._tree.TreeExplainer object at 0x11fbcf750>
The computed AUC on the X_test used to build datadrift_classifier is equal to: 0.7822871980130955
[ ]:
SD.plot.generate_historical_datadrift_metric() # works if date_compile_auc and/or datadrift_file are filled
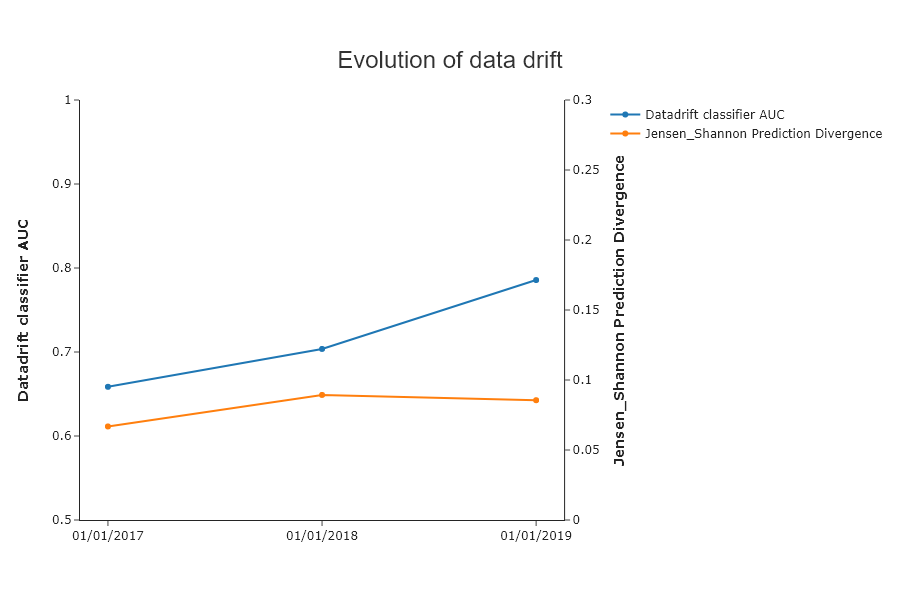
This result is interesting because we see that the auc is very high, but not the Jensen Shannon datadrift. This shows the interest of the latter.
[ ]:
SD.plot.scatter_feature_importance() # works if deployed_model is filled
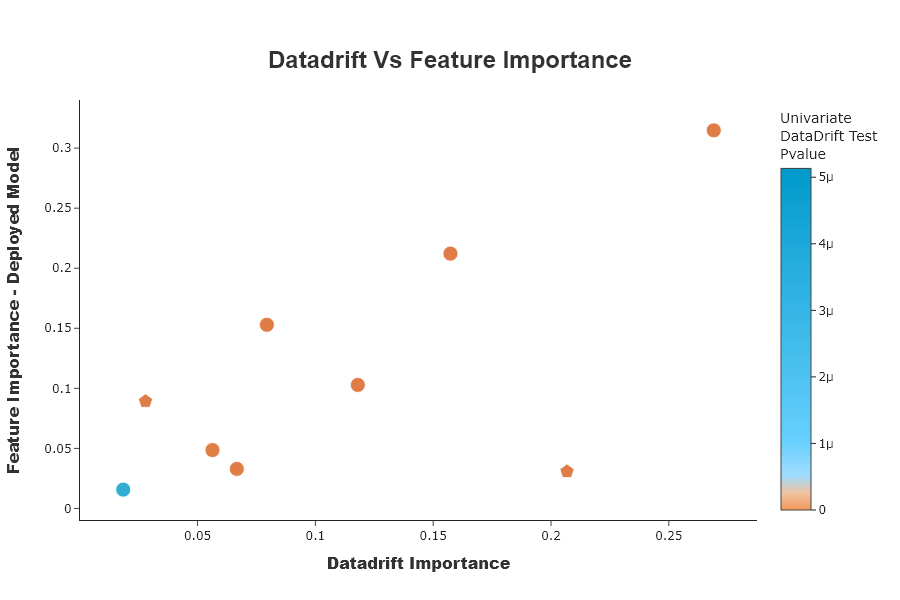
the first 3 variables that explain the data drift by the auc of datadrift classifier are not very important for the model
[ ]:
SD.plot.generate_fig_univariate(df_all=SD.df_predict,col='Score',hue="dataset") # works if deployed_model is filled
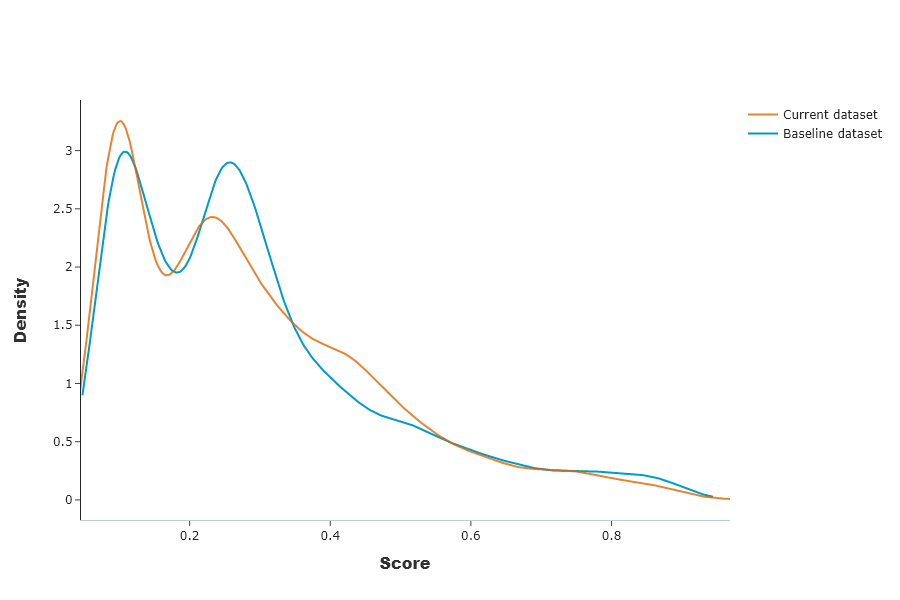
We can see that despite the data drift, the impact on predictions is quite small
[ ]:
SD.plot.generate_indicator(
fig_value=SD.js_divergence,
height=280,
width=500,
title="Jensen Shannon Datadrift",
min_gauge=0,
max_gauge=0.2,
) # works if deployed_model is filled
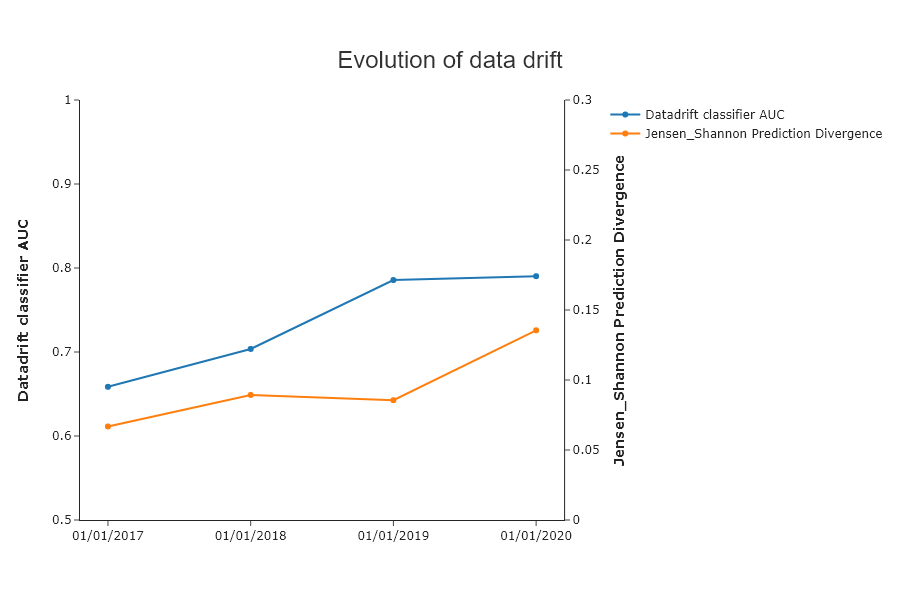
Compile Drift et generate report for Year 2020¶
[37]:
SD = SmartDrift(df_current=X_df_2020,
df_baseline=X_df_learning,
deployed_model=model, # Optional: put in perspective result with importance on deployed model
encoding=encoder # Optional: if deployed_model and encoder to use this model
)
[38]:
SD.compile(full_validation=True, # Optional: to save time, leave the default False value. If True, analyze consistency on modalities between columns.
date_compile_auc = date(2020,1,1), # Optional: useful when computing the drift for a time that is not now
datadrift_file = "car_accident_auc.csv" # Optional: name of the csv file that contains the performance history of data drift
)
INFO: Shap explainer type - <shap.explainers._tree.TreeExplainer object at 0x1212442b0>
The computed AUC on the X_test used to build datadrift_classifier is equal to: 0.797392480824591
[ ]:
SD.plot.generate_historical_datadrift_metric() # works if date_compile_auc and/or datadrift_file are filled
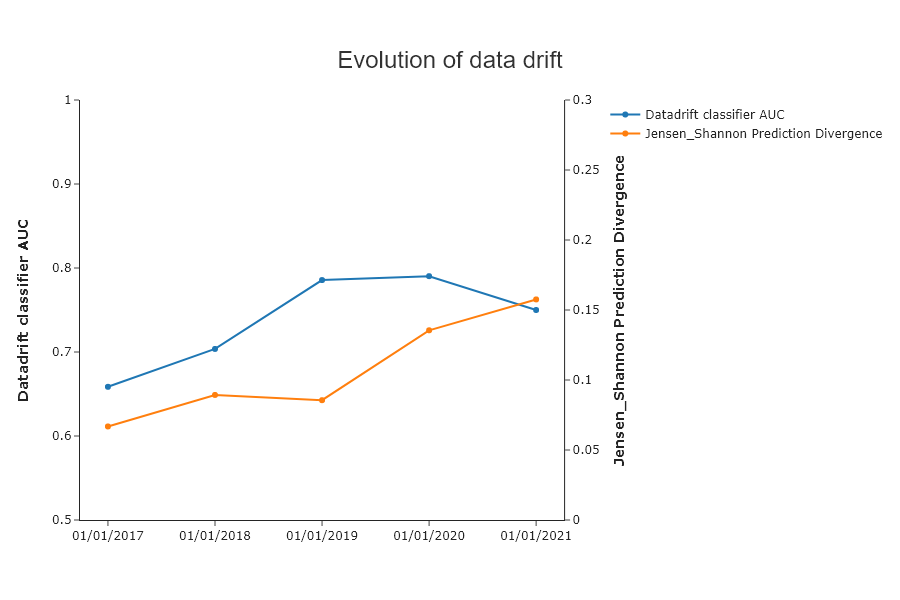
Compile Drift et generate report for Year 2021¶
[40]:
SD = SmartDrift(df_current=X_df_2021, df_baseline=X_df_learning, deployed_model=model, encoding=encoder)
[41]:
SD.compile(full_validation=True,
date_compile_auc = date(2021,1,1), #optionnal, by default date of compile
datadrift_file = "car_accident_auc.csv"
)
INFO: Shap explainer type - <shap.explainers._tree.TreeExplainer object at 0x121244b00>
The computed AUC on the X_test used to build datadrift_classifier is equal to: 0.7480269190539165
[ ]:
SD.plot.generate_historical_datadrift_metric()
[43]:
SD.generate_report(
output_file='report_car_accident_datadrift_2021.html',
title_story="Data drift",
title_description="""Car accident Data drift 2021""", # Optional: add a subtitle to describe report
project_info_file="../../eurybia/data/project_info_car_accident.yml" # Optional: add information on report
)
[ ]: